我們在學校的學習,大致上會需要買(或找)書、讀書、考試以及看成績,機器學習的概念也與之非常相似,但我們會稱之為收集資料、訓練模型、測試模型和效果評估,並且為了將資料轉換成機器可以運算的格式,通常還會在收集資料與訓練模型之間,加上一個叫做特徵抽取的步驟。以下將大略的介紹收集資料和訓練模型的相關概念(效果評估會在下一個子篇章介紹),更多細節會在後面的應用章節提及。
我們以「使用身高體重分辨生理性別」作為一個範例的研究題目來說明。為了這個題目,你首先可能需要找一堆人,然後測量他們的身高體重以及紀錄性別,這就是收集資料以及特徵抽取(feature extraction)。而如果已經有人公開提供資料,例如這裡,你也可以在符合授權條款的情況下,用這些資料來做實驗。需要注意的是,特徵抽取並不是隨便亂抽就可以,例如上胸圍和下胸圍的差距可能是個很有幫助的特徵;而手臂長度跟身高很相關,所以可能幫助沒那麼大;至於像是鼻孔有幾個或是腿有幾條,這種除非遭遇疾病或意外否則不會有差異的值,就幾乎不會有幫助。
接著,我們會把資料分成兩個或三個子集,分別為訓練集(training set),開發集(development set) ,以及測試集(test set),分別做為訓練、驗證,以及測試用;其中,開發集又稱驗證集(validation set),在兩個子集(僅有訓練集和測試集)的情況下,亦可由訓練集視實際需要來進一步拆分。訓練的概念,是使用一堆你知道身高體重和性別的資料,亦即使用訓練集來學出模型;通常來說,模型架構選用的愈複雜,或者學習的時間愈久,則模型在這部分會學得愈好。測試的意思則是,把從測試集抽取出的特徵輸入進訓練好的模型,然後把模型的輸出跟答案來比對分數,就像你讀完書上考場一樣的道理。
下面的圖片,是使用前述的公開資料集收集的特徵,以及切分好的訓練集和測試集進行繪製。圖片上的線是依據訓練資料,用人工隨便切一刀的線性分類器,並期望女性資料位在線的左邊,男性資料位在線的右邊,如果你看到有相反的狀況,就代表你發現了這個分類器的分類錯誤:
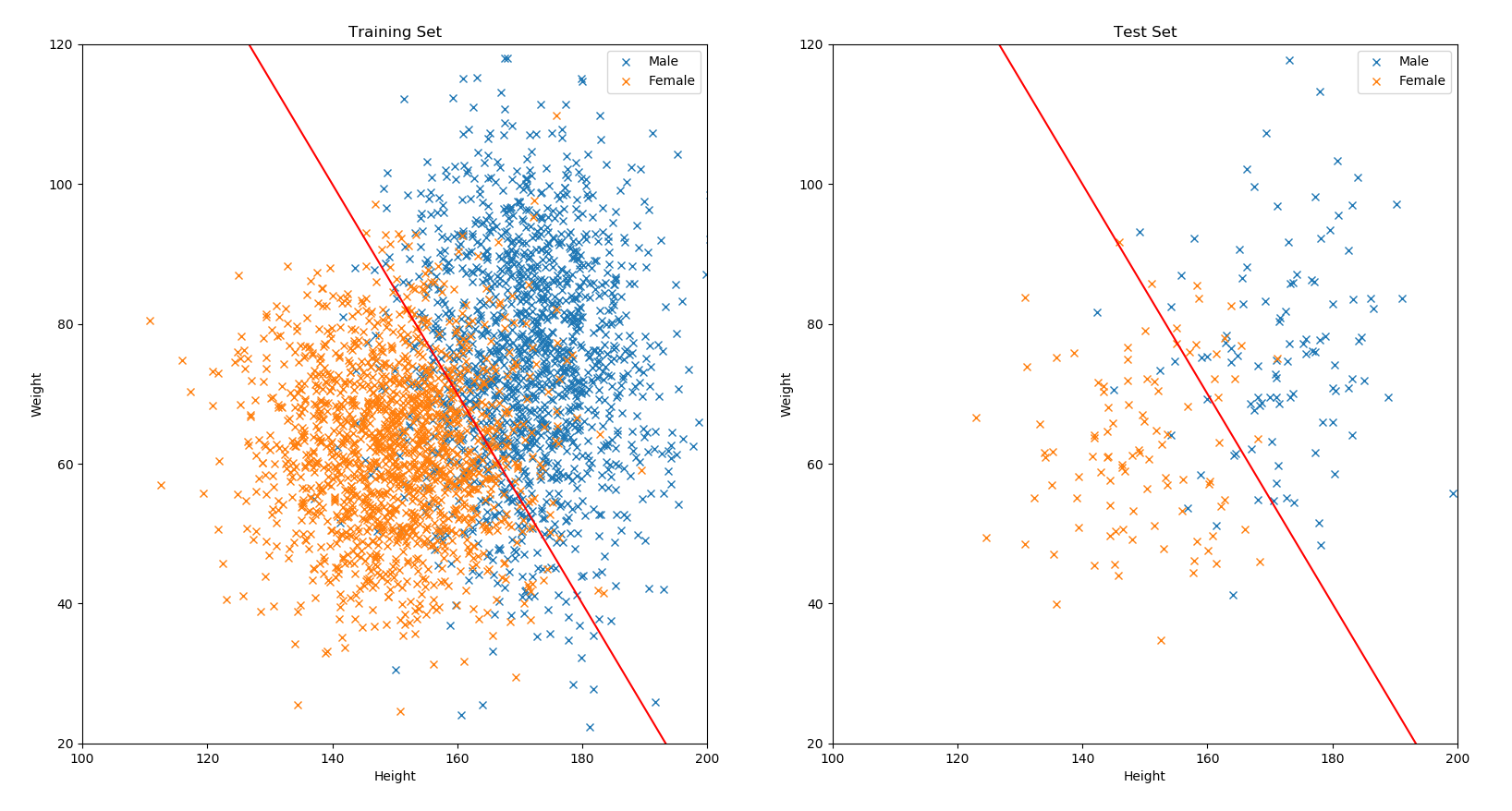
另外,上述範例的問題,因為是分辨不同的種類,所以稱為分類問題;而如果你希望預測的目標是連續的數字,例如從身高預測體重,則稱為回歸問題。兩者會在模型選用和評估等等細節上有些差異,但大致的概念差不多。
此外,有時候你會發現,讀書時讀太久把書背太死,考試時題型變化一點點可能就不會寫;對應到機器學習的情境下,就是模型訓練了很久之後,雖然能把訓練集的模樣學得更透徹,但是到測試集上的表現就會炸掉,這樣的情況稱為過擬合(over fitting)。因此,為了防止模型過擬合,為了保護模型的穩定,就該輪到驗證集登場,我們可以在模型訓練當中,不時的將目前的模型用驗證集來測試,萬一由驗證集算出來的準確度下降了,就代表過擬合可能已經發生了。這樣子的做法是一個訓練集對一個驗證集,我們甚至可以把訓練集和驗證集混在一起,再拆成 K 份來使用,輪流用 K - 1 份訓練和 1 份驗證,稱為 K 折交叉驗證( K-fold cross validation)。